시작하며
RNN은 주로 NLP에서 많이 사용되는 모형입니다. RNN은 이외에도 여러가지 이전 관측치의 값이 다음 관측치의 값에 영향을 미치는 시계열류의 데이터를 모델링하기 위해 많이 사용됩니다. RNN 이전에는 주로 ARIMA, Markov Random Field 등으로 풀던 문제였습니다. 문장을 하나의 숫자열로 표현하는 것은, 앞에서도 언급한 바 있지만, 어떻게든 token을 숫자화시키고 그 token을 하나의 값으로 나타내는 과정입니다. 어떠한 방법이든 token의 정보, 그리고 그 token들이 가지고 있는 여러가지 관계성 등이 유지가 되기만 한다면, 어떠한 방법도 사용할 수 있습니다. 그 방법들 중에서 인간이 문장을 인지하는 방식을 묘사하는 방식으로 모형을 고안된 방법들이 있는데, 대표적인 예가 RNN과 CNN, 그리고 최근에 각광받고 있는 Attention mechanism입니다. 문장에 등장하는 embedding된 단어의 요약을 하나의 pattern으로 보고 그것을 인식하여 단순히 분류하고 있다고 한다면, 보다 인간이 문장을 이해하는 방식을 따라하므로써, RNN과 CNN은 더욱 성능이 좋은 모형을 만들어 낼 수 있습니다. Sentiment analysis를 넘어선 neural translation에서는 보다 복잡한 모형들이 필요한 이유이기도 합니다.
Gluon에서 LSTM을 어떻게 사용하는지에 대한 내용을 찾아보기는 쉽지 않습니다. 그리고 API의 document 자체도 그리 훌륭하지는 않지만, 예제도 거의 찾아볼 수 없습니다. RNN에 대한 기본적인 내용들은 이미 많은 곳에서 알려져 있으니, sentiment analysis 과정을 통해 gluon에서 어떻게 LSTM 등 RNN을 사용하는지를 중심으로 알아보겠습니다.
Architecture
상상할 수 있는 구조는 아주 다양합니다. 단순히 hidden layer를 쓸 수도 있고, hidden layer를 여러층 사용할 수도 있을 것입니다. 각 time step의 output을 평균해서 사용할 수도 있을 것입니다. 본인의 기억을 위해 각각의 구조를 gluon으로 어떻게 반영하는지 정리해 보겠습니다. 그러면서 gluon LSTM API의 사용법에 대해서 자세히 기록하겠습니다.
LSTM cell의 구조
많은 곳에서 이미 LSTM의 구조에 대한 정보는 얻을 수 있습니다. 그럼에도 불구하고 한번 주지해야 할 사실은 LSTM에는 이전 time step에서 2개의 정보를 활용한다는 사실입니다. 다음의 그림에서 보면 cell state와 hidden state는 이전 time step의 결과물을 그 다음 time step의 입력으로 받아들입니다.
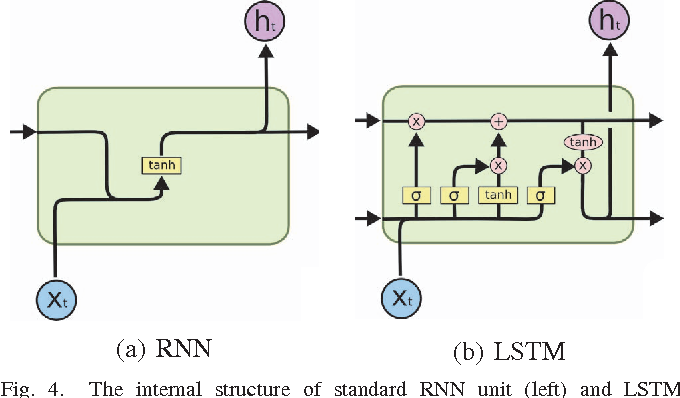
그냥 RNN과 GRU은 모두 1개의 hidden layer만 이전 input으로 받아들입니다. 이게 구현 상에서 좀 헷갈리는 면입니다. LSTM에서는 초기 정보를 입력 값으로 넣어주어야 하는데, 그 정보가 RNN 혹은 GRU와 사뭇 다를 수 있다는 겁니다. LSTM은 두개의 ndarray를 list의 형태로 넘깁니다. 그 list의 첫번째 ndarray는 hidden state에 대한 초기값을, 두번째 ndarray는 cell state에 대한 초기값을 뜻합니다. Document에는 이에 대한 명백한 언급 없이, 길이가 2인 list를 입력해야 한다고만 나와 있습니다. 자세한 내용은 source를 읽어야 파악할 수 있다는 거구요. 보다 자세한 설명이 있었으면 아주 좋았을 텐데 좀 아쉬운 부분입니다.
1개의 hidden layer의 마지막 layer를 사용하는 경우
전체 코드는 Single Hidden State를 참조하시기를 바랍니다.
가장 먼저 알아볼 기본 구조는 Token을 embedding 한 후에 이를 LSTM layer를 통과시킨 후, 그 결과물을 classifier의 입력으로 사용하는 구조입니다.
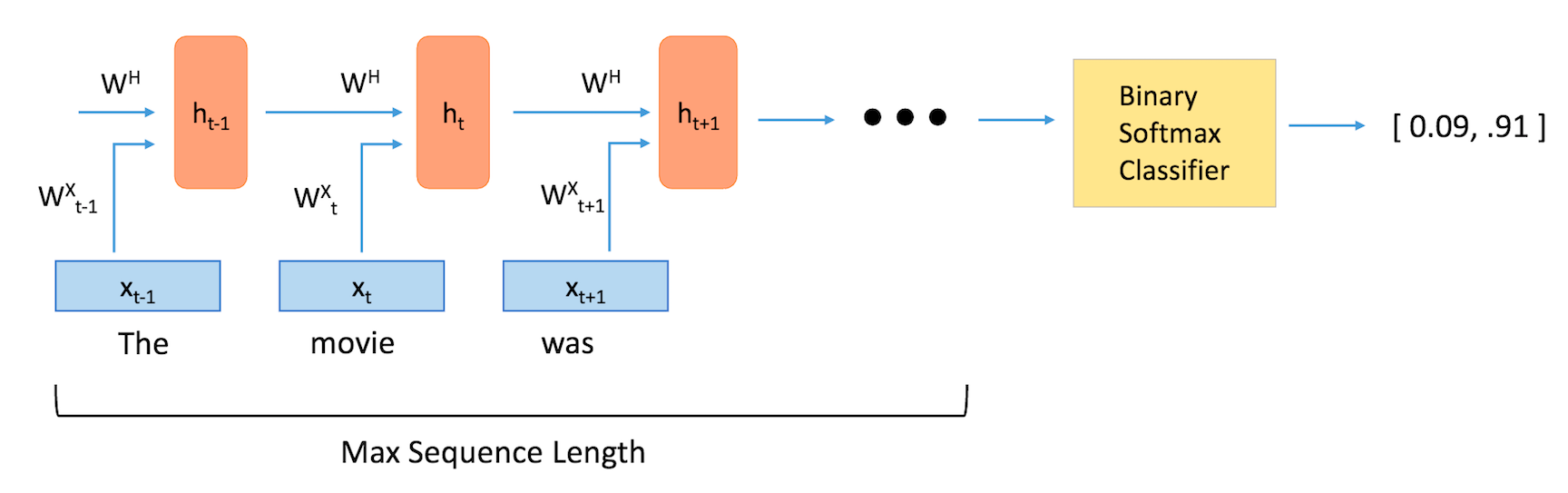
과거의 정보를 모두 감안/반영하는 LSTM의 구조상, 제일 마지막의 hidden state는 문장에 대한 모든 정보를 압축해 놓은 것이라고 생각한다면 마지막 time step에서의 hidden state만 활용해서 classifier의 입력으로 사용할 수 있습니다.
class Sentence_Representation(nn.Block):
def __init__(self, emb_dim, hidden_dim, vocab_size, dropout = .2, **kwargs):
super(Sentence_Representation, self).__init__(**kwargs)
self.vocab_size = vocab_size
self.emb_dim = emb_dim
self.hidden_dim = hidden_dim
with self.name_scope():
self.hidden = []
self.embed = nn.Embedding(vocab_size, emb_dim)
self.lstm = rnn.LSTM(hidden_dim, dropout = dropout \
, input_size = emb_dim, layout = 'NTC')
def forward(self, x, hidden):
embeds = self.embed(x) # batch * time step * embedding: NTC
lstm_out, self.hidden = self.lstm(embeds, hidden)
return lstm_out, self.hidden
위에 있는 코드는 어떤 문장이 주어졌을 때 sentence representation을 LSTM을 기반으로 하는 코드입니다. 문장을 하나의 벡터로 표현하는 과정에서 위의 코드는 주어진 문장을 embedding layer를 통과시킨 결과물을 LSTM layer의 input으로 사용합니다.
embedding layer는 vocab_size를 input으로 받아서 객체를 만들고, 실제 학습을 위한 데이터는 token index의 sequence를 활용합니다.
self.embed = nn.Embedding(vocab_size, emb_dim)
위의 layer를 통과해서 나온 embedding 벡터는 (Batch size $\times$ Sentence length $\times$ Embedding dimension)이 됩니다.
input의 예를 들면, 전체 5개의 단어만 존재하고, 한 문장이 3개의 단어로 이루어져 있으며, 우리가 고려하는 최대의 문장 길이가 7이라고 하면, 다음과 같은 input을 가집니다. $\Rightarrow$ [5, 2, 4, 0, 0, 0, 0]
이렇게 embedding된 결과물은 lstm에서 input으로 사용되는데요. LSTM layer는 다음과 같이 선언됩니다.
self.lstm = rnn.LSTM(hidden_dim, dropout = dropout \
, input_size = emb_dim, layout = 'NTC')
가장 중요하게 볼 점 중에 하나는 layout keyword인데요. 여기에서 NTC로 적어줌으로써, Embedding 결과물을 transpose하지 않고 바로 입력으로 사용할 수 있습니다. transpose 연산은 상대적으로 아주 큰 연산이므로 피하는 것이 좋겠죠?
그런 후에 hidden state의 정보를 뽑아서 하나의 벡터로 문장을 표현하게 됩니다.
간단하게 다음과 같이 classifier를 정의합니다.
classifier = nn.Sequential()
classifier.add(nn.Dense(16, activation = 'relu'))
classifier.add(nn.Dense(8, activation = 'relu'))
classifier.add(nn.Dense(1))
지금 다루는 데이터는 워낙 분류가 잘 되는 쉬운 문제라 위와 같이 간단한 형태의 classifier면 충분히 좋은 성능이 나옵니다.
이렇게 두개 network를 정의하셨으면, 다음처럼 꼭 parameter를 initialize하시구요.
sen_rep.collect_params().initialize(mx.init.Xavier(), ctx = context)
classifier.collect_params().initialize(mx.init.Xavier(), ctx = context)
위의 두 network를 input으로 받아서 다음과 같이 최종 classifier를 정의합니다.
class SA_Classifier(nn.Block):
def __init__(self, sen_rep, classifier, batch_size, context, **kwargs):
super(SA_Classifier, self).__init__(**kwargs)
self.batch_size = batch_size
self.context = context
with self.name_scope():
self.sen_rep = sen_rep
self.classifier = classifier
def forward(self, x):
hidden = self.sen_rep.lstm.begin_state(func = mx.nd.zeros, batch_size = self.batch_size, ctx = self.context)
_, _x = self.sen_rep(x, hidden) # Use the last hidden step
# Extract hidden state from _x
_x = nd.reshape(_x[0], (-1, _x[0].shape[-1]))
x = self.classifier(_x)
return x
여기서 구현 상에서 중요한 점은 hidden은 길이가 2인 list의 형태를 가진다는 점입니다. 물론, LSTM layer가 자체적으로 begin_state라는 method를 제공하기는 하지만, 앞으로 더 복잡한 모형들을 구현하다 보면, 다른 RNN과는 달라 헤맬 수 있는 부분입니다.
우리가 필요한 것은 각 time step의 output이 아니므로, 첫 번째 return값은 무시하고, hidden state 정보를 가지고 있는 두 번재 return값만 받아옵니다. 말씀 드린 것처럼, LSTM이므로 다음과 같이 hidden state를 뽑아내기 위해서는 _x의 첫 번째 원소를 가져와야 합니다.
_x = nd.reshape(_x[0], (-1, _x[0].shape[-1]))
참고로 말씀드리자면, _x의 크기는 (Batch size $\times$ Hidden State)가 됩니다. _x를 classifier의 input으로 넣어서 DNN을 이용해서 최종 분류 작업을 진행합니다.
결과
워낙 쉬운 데이터셋이다 보니 accuracy 0.9라는 높은 성능을 얻습니다. 그것도 불과 5 epoch 이내에서 말입니다. 보다 자세한 결과물을 싣지는 않겠습니다. 그냥 위에 링크되어 있는 코드를 한번씩 돌려보시면 큰 무리 없이 이해하실 수 있을 것입니다. 다음은 LSTM layer가 2개인 경우 Gluon으로 어떻게 구현할 수 있는지를 간단하게 설명하겠습니다.