시작하며
LSTM에서 1개의 LSTM layer를 이용해서 문장을 표현하는 방법을 지난 블로그에서 알아보았습니다. 말씀드린 것처럼 sentiment analysis를 위한 정보를 문장으로부터 뽑아내는 방법에는 여러가지가 있습니다. 오늘은 Bidirectional LSTM을 이용하는 방법에 대해서 알아보겠습니다. 두가지 방법을 알아볼텐데요. 하나는 LSTMCell을 이용해서 직접 Bidirection LSTM을 구현하는 방법과 다른 하나는 LSTM Layer를 이용해서 간단하게 구하는 방법입니다.
그렇다면 간단하게 할 수 있는 작업을 왜 어렵게 두가지로 나눠서 보느냐? 최근 트렌드는 어떻게 보면 attention mechanism이 주도한다고 해도 과언이 아닙니다. 이렇게 hot한 Attention mechansim을 사용하기 위해서는 각 time step에서의 hidden state 값들을 모두 뽑아내야 하는데요. 그게 LSTM layer만을 사용해서는 얻기가 어렵습니다. 그 때는 LSTMCell을 사용해야 합니다.
이번 글은 Sentiment analysis 자체에 대한 내용이라기 보다는 gluon의 LSTM API 같은 성격을 지니겠네요.
Architecture
이번에는 다음과 같이 Bidirectional LSTM을 통해서 문장을 표현하는 방법을 생각해 보겠습니다.

Googling을 해보니 위와 같은 구조가 보입니다. 대체적으로는 맞는 그림인 것 같습니다만, 오류가 있습니다. 마지막 time step의 경우 역방향 LSTM은 충분히 문장 전체를 학습하지 못한 채 문장을 구분하는 데에 사용이 되고 맙니다. 사실 잘못된 그림이죠. 생각보다 잘못된 그림들, 그래서 실제로 구현에 있어서 방해가 되는 그림들이 많습니다. 제가 그려보니깐 사실 오류 없이 그리기도 쉽지는 않습니다. 개개인의 경험이 중요한 이유인 것 같습니다.
다음 그림이 더 정확하다고 보겠습니다.

그래서 forward LSTM의 경우에는 마지막 time step의 hidden state값을, reverse LSTM의 경우에는 첫번째 time step의 hidden state값을 가져 오는 게 맞습니다. Gluon으로 구현을 해보도록 하죠.
Bieirectional LSTM은 그냥 독립적인 두개의 LSTM
전체 코드는 Bidirectional LSTM를 참조하시기를 바랍니다.
말한 것과 같이 가장 쉽게는 두개의 LSTM을 구해주면 됩니다. 단지 방향이 다를 뿐이지요. 가장 쉽게 Bidirectional LSTM을 구현하는 방법은 LSTM layer의 bidirection option을 사용하는 것입니다.
self.lstm = rnn.LSTM(HIDDEN_DIM, dropout = dropout \
, input_size = EMB_DIM \
, bidirectional = True \
, layout = 'NTC')
그 결과 hidden state는 LSTM layer 개수의 두배만큼 돌려줍니다. 얻어진 행렬은 (2 $\times$ Batch size $\times$ Hidden Layer)가 됩니다. 그러므로, classifier에 bidirectional LSTM의 결과물을 넣을 때에는 reshape을 해주어야 합니다.
class SA_Classifier(nn.Block):
def __init__(self, sen_rep, classifier, batch_size, context, **kwargs):
super(SA_Classifier, self).__init__(**kwargs)
self.batch_size = batch_size
self.context = context
with self.name_scope():
self.sen_rep = sen_rep
self.classifier = classifier
def forward(self, x):
hidden = self.sen_rep.lstm.begin_state(func = mx.nd.zeros, batch_size = self.batch_size, ctx = self.context)
_, _x = self.sen_rep(x, hidden) # Use the last hidden step
# Extract hidden state from _x
_x = nd.reshape(_x[0], (-1, 2 * _x[0].shape[-1]))
x = self.classifier(_x)
return x
forward method의 마지막에서 두번째 라인이 그 라인에 해당합니다.
LSTMCell
LSTMCell은 좀더 advanced 된 API로 LSTM을 좀더 세밀하게 control할 수 있는 API입니다. 아주 단순한 경우에는 LSTM layer를 그대로 활용해도 큰 문제가 없지만, bidirectional LSTM에서는 LSTM layer를 time step 관점에서 거꾸로 적용을 해야 합니다. 다음의 코드를 참고하시기 바랍니다.
class Sentence_Representation(nn.Block):
def __init__(self, emb_dim, hidden_dim, vocab_size, dropout = .2, **kwargs):
super(Sentence_Representation, self).__init__(**kwargs)
self.vocab_size = vocab_size
self.emb_dim = emb_dim
self.hidden_dim = hidden_dim
with self.name_scope():
self.f_hidden = []
self.b_hidden = []
self.embed = nn.Embedding(self.vocab_size, self.emb_dim)
self.drop = nn.Dropout(.2)
self.f_lstm = rnn.LSTMCell(self.hidden_dim // 2)
self.b_lstm = rnn.LSTMCell(self.hidden_dim // 2)
def forward(self, x, _f_hidden, _b_hidden):
embeds = self.embed(x) # batch * time step * embedding
self.f_hidden = _f_hidden
self.b_hidden = _b_hidden
# Forward LSTM
for i in range(embeds.shape[1]):
dat = embeds[:, i, :]
_, self.f_hidden = self.f_lstm(dat, self.f_hidden)
# Backward LSTM
for i in np.arange(embeds.shape[1], 0, -1):
dat = embeds[:, np.int(i - 1), :] # np.int() necessary
_, self.b_hidden = self.b_lstm(dat, self.b_hidden)
x = nd.concat(self.f_hidden[0], self.b_hidden[0], dim = 1)
return x
LSTMCell의 결과물은 LSTM과 비슷하기는 하지만 모양이 약간 다릅니다. LSTMCell은 layer가 여러개일 것을 가정하지 않습니다. 그 대신에 만약 여러개의 layer를 쌓아야 한다면, 직접 loop 문을 통해서 layer를 쌓아야 합니다. 그러므로, LSTMCell의 결과물은 (Batch size $\times$ Hidden dim)입니다. 반면 LSTM은 (Layer 개수 $\times$ Batch size $\times$ Hidden dim)을 hidden state 값으로 돌려줍니다. 이전 blog에서는 hidden state를 reshape해주는 단계를 거쳤는데요, 여기서는 그런 단계를 거칠 필요가 없습니다. 그냥 hidden state를 concat 해주기만 하면 됩니다.
x = nd.concat(self.f_hidden[0], self.b_hidden[0], dim = 1)
모든 time step의 hidden state에 접근
지금까지는 최종 Hidden state의 정보만을 classification에 활용하는 형태였습니다. 그런데 사실 꼭 그렇게만 사용할 필요는 없죠. 각 time step의 hidden state들을 모두 활용할 수도 있을 것입니다. 다음의 그림과 같이 구조를 만들 수도 있겠죠.
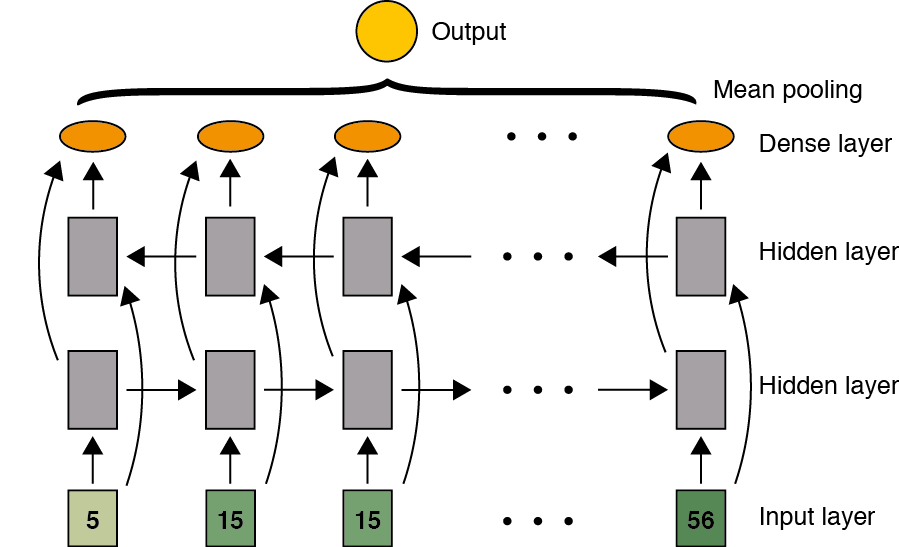
결국 매 time step에서 forward LSTM과 backward LSTM을 concatenate한 후 이들의 평균을 sentence representation으로 봅니다. 그렇게 하기 위해서는 매 time step마다 hidden state의 값을 알아야 하는데요. 이 때 LSTMCell layer를 매 time step마다 update해야 합니다. 매 time step이 update될 때마다 그 hidden state를 저장한 후 저장된 matrix를 concat해 주어야 합니다. 그런 후에 평균을 내는 것이지요. 이런 과정은 다음의 코드로 구현할 수 있습니다.
class Sentence_Representation(nn.Block): ## Using LSTMCell : Average entire time step
def __init__(self, emb_dim, hidden_dim, vocab_size, dropout = .2, **kwargs):
super(Sentence_Representation, self).__init__(**kwargs)
self.vocab_size = vocab_size
self.emb_dim = emb_dim
self.hidden_dim = hidden_dim
with self.name_scope():
self.f_hidden = []
self.b_hidden = []
self.embed = nn.Embedding(self.vocab_size, self.emb_dim)
self.f_lstm = rnn.LSTMCell(self.hidden_dim // 2)
self.b_lstm = rnn.LSTMCell(self.hidden_dim // 2)
def forward(self, x, _f_hidden, _b_hidden):
f_hidden = []
b_hidden = []
self.f_hidden = _f_hidden
self.b_hidden = _b_hidden
embeds = self.embed(x) # batch * time step * embedding
# Forward LSTM
for i in range(embeds.shape[1]):
dat = embeds[:, i, :]
_, self.f_hidden = self.f_lstm(dat, self.f_hidden)
f_hidden.append(self.f_hidden[0])
# Backward LSTM
for i in np.arange(embeds.shape[1], 0, -1):
dat = embeds[:, np.int(i - 1), :] # np.int() necessary
_, self.b_hidden = self.b_lstm(dat, self.b_hidden)
b_hidden.append(self.b_hidden[0])
f_hidden.reverse()
_hidden = [nd.concat(x, y, dim = 1) for x, y in zip(f_hidden, b_hidden)]
h = nd.concat(*[x.expand_dims(axis = 0) for x in _hidden], dim = 0)
h = nd.mean(h, axis = 0)
return h
역방향 LSTM과 순방향 LSTM은 서로 반대방향이므로, concat할 때 방향을 바꾸어주어야 합니다. 그 외에는 크게 문제될 부분은 없어 보입니다. 그렇게 concat한 후에는 각 time step으로부터 얻은 hidden state를 평균을 내야 합니다. hidden state의 dimension은 (Time Step $\times$ Batch size $\times$ Hidden dimension)이므로, 0번 축으로 평균을 냅니다.
각 time step에서 output만을 활용한다면..
각 time step에서의 LSTM output은 $o_t * h_t$로 정의됩니다. 여기서 $h_t$는 $t$ step에서의 hidden state를 의미합니다. Gluon에서는 각 time step의 output을 이요할 때, BidirectionalCell이라는 함수를 사용하면 쉽게 그 결과를 뽑을 수 있는데요. 다음과 같이 작성하면 됩니다. BidirectionalCell에는 LSTMCell 2개가 input으로 들어가서 문장의 순방향 및 역방향 정보를 scan하게 됩니다.
class Sentence_Representation(nn.Block):
def __init__(self, **kwargs):
super(Sentence_Representation, self).__init__()
for (k, v) in kwargs.items():
setattr(self, k, v)
with self.name_scope():
self.embed = nn.Embedding(self.vocab_size, self.emb_dim)
self.drop = nn.Dropout(.2)
self.bi_rnn = rnn.BidirectionalCell(
rnn.LSTMCell(hidden_size = self.hidden_dim // 2), #mx.rnn.LSTMCell doesnot work
rnn.LSTMCell(hidden_size = self.hidden_dim // 2)
)
self.w_1 = nn.Dense(self.d, use_bias = False)
self.w_2 = nn.Dense(self.r, use_bias = False)
def forward(self, x, hidden):
embeds = self.embed(x) # batch * time step * embedding
h, _ = self.bi_rnn.unroll(length = embeds.shape[1] \
, inputs = embeds \
, layout = 'NTC' \
, merge_outputs = True)
# For understanding
batch_size, time_step, _ = h.shape
# get self-attention
_h = h.reshape((-1, self.hidden_dim))
_w = nd.tanh(self.w_1(_h))
w = self.w_2(_w)
_att = w.reshape((-1, time_step, self.r)) # Batch * Timestep * r
att = nd.softmax(_att, axis = 1)
x = gemm2(att, h, transpose_a = True) # h = Batch * Timestep * (2 * hidden_dim), a = Batch * Timestep * r
return x, att
간단히 그 결과는 unroll이라는 method로 얻을수 있겠습니다. 해당 method는 각 time step에서의 ouput을 첫번째 결과물로, 최종 hidden state의 값을 두번째 결과물로 return합니다. 우리는 첫번째 결과물만 중요하므로, 위와 같이 첫번째 return 값만 가져와서 작업을 진행할 수 있습니다. 코드는 여기에 정리되어 있습니다. 참고하세요.
결과
여전히 0.99의 accuracy를 보이네요. 3,149개의 리뷰 중에 총 38개의 리뷰가 오분류되었습니다. 그 중 하나를 보아하니, 제가 봐도 좋다는 건지 나쁘다는 건지 헷갈리네요.

이건 인정. 하지만, 나중에 보다 어려운 데이터를 바꿔가면서 어떤 식으로 LSTM을 응용했을 때 성능이 좋아지고 나빠지는지를 알아봐야 할 것 같습니다.