Introduction
Let’s think about the way human understand sentence. We read the sentence from left to right (it is not the case in the ancient asisan culture though) word by word memorizing the meaning of words first. Words themselves may have very different meaning depending where they are placed or how they were used. To understand real meaning of words, we break the sentence down into smaller phrases, groups of words, to get the right meaning of words in the context of sentence. Lastly, we weave the meanings from phrases to understand the sentence finally. How to mimic this behavior or reading?
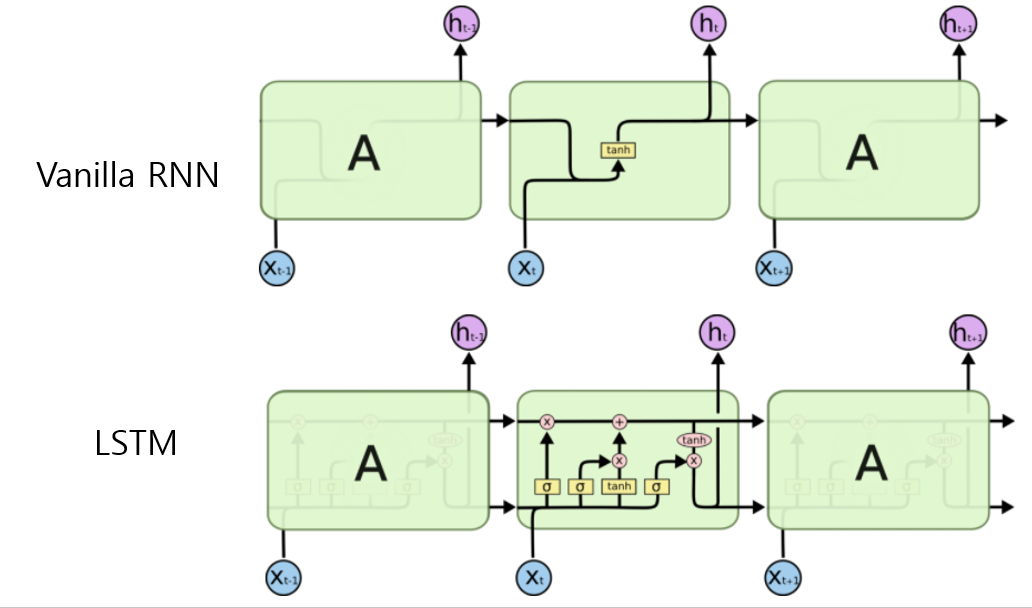
Recurrent network is not enough
Recurrent neural network models the way human’s reading behavior by taking the sentance as sequence of words(possibly, token can be better expression, here we stick with word) in order. It calculates conditional probability given the previously read words. Especially, LSTM can adjust itself the amount of memory for each word to get best understanding of sentence. RNN also can be used to model hierarchical way of understanding sentence (word - phrase - sentence - paragrph structure) by stacking layers.
Bidirectional RNN can be another option for better understanding the sentence. From time to time, the word at the end of sentence can be helpful in understanding the words located in the earlier part of sentence. Bidirectional RNN allows memory cells to collect information from the back to front of sentence. By concatenating RNN cells from both forward and backward direction, meaning of words get clearer than just using single RNN cell.
One of the biggest issues with RNN is speed and parallelization. Sequential nature of RNN prevents it from parallel programming and it ends up with very slow training speed. To make it even worse, memory cells have many parameters compared to CNN and it is another source of inefficiency.
CNN can do something about it.
CNN is well-known for picking spatial information and widely used for image related tasks. Understanding sentence in hierachical manner can be considered as a process of recognizing low-level local feature and abstracting them into higher concept. So why not using CNN in sentence reprentation?
Adidtionally, as CNN utilize only words around the word that the algorithm focusing on, we can easily break down into pieces and train those pieces in parallel. So Kim et al. (2014) proposed a simple algorithm that employ CNN for sentiment analysis. Let’s understand some detail about it.
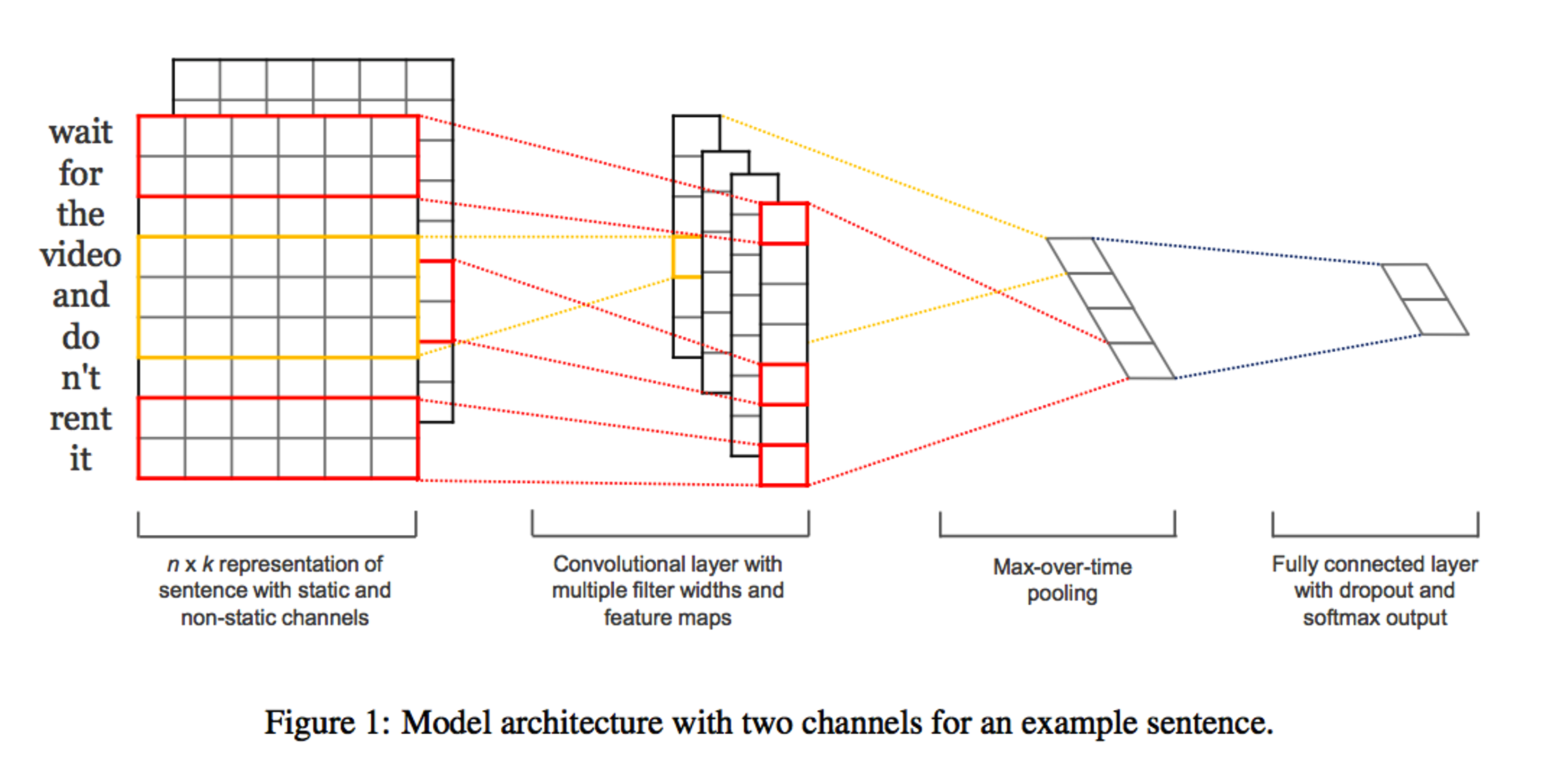
CNN architecture for sentiment analysis.
In this article, we will implement Kim et al. (2014). Not exactly but very similarly keeping their idea.
The following visual came from the paper and if you understand this clearly, I think you are almost there.
NOTE: Based on my personal experience, most of papers are not kind enough to tell every detail about their idea and it is very hard to implment their idea correctly without those implicit elements hardly found in the original paper. This paper, however, seems to be relatively straightforward to implement.
More fancy plot with the same idea can be found below.
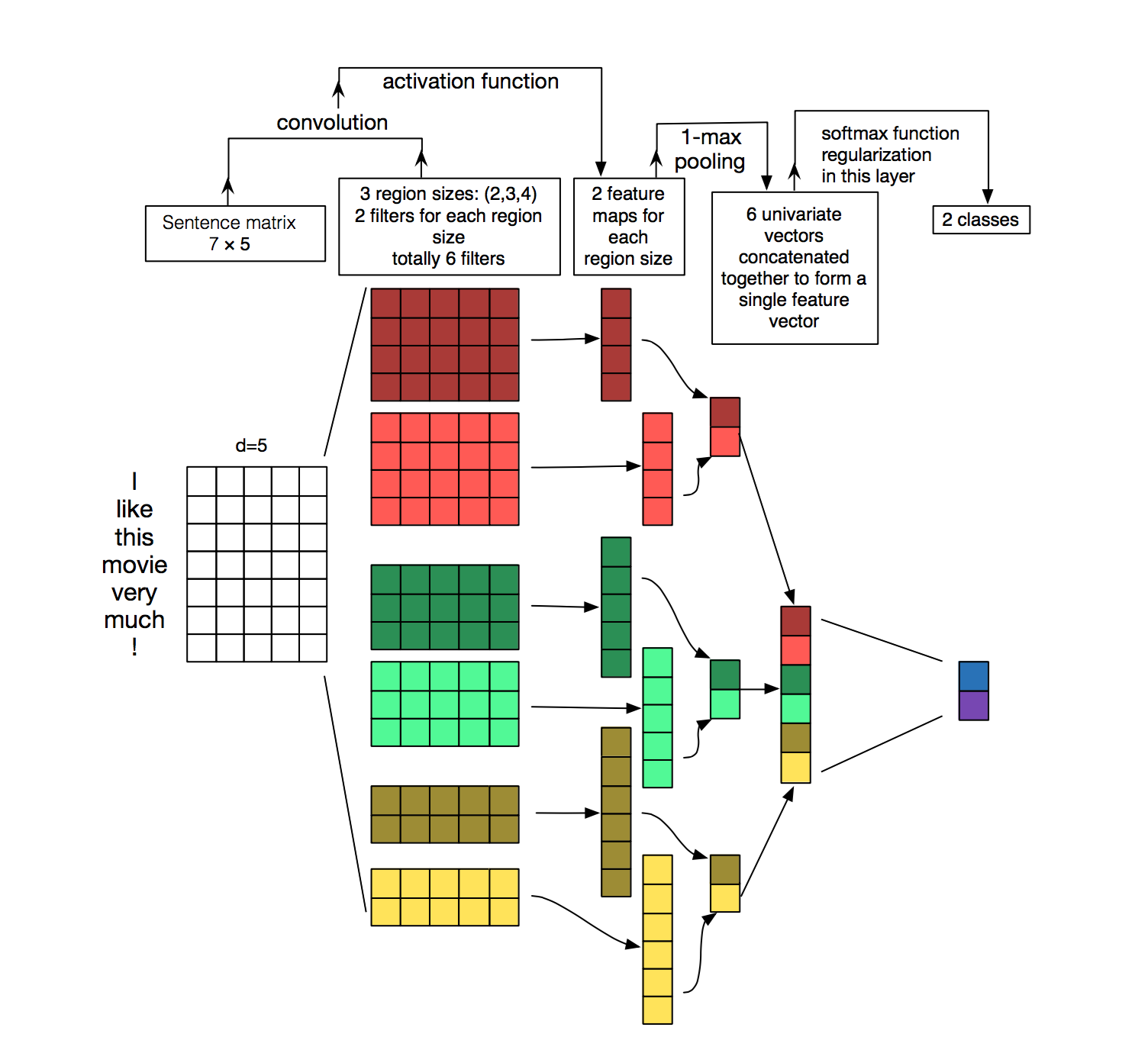 It consitst of couple of 1D convolution layer with different kernel size on word embeddings. By doing this, we can retrieve information from various word groups.
It consitst of couple of 1D convolution layer with different kernel size on word embeddings. By doing this, we can retrieve information from various word groups.
The feature maps obtained by applying 1D convolution layers sequentially from the start to the end of sentence are fed into max-pooling layer to summarize those $N - k + 1$, feature maps into single number. Here $N$ is the number of words in sentence and $k$ is the size of 1D convolution filter. Concatenating those outputs from max-pooling layer (just a scalar), we get a vector as long as number of 1D convolution layers and it is going to be input for a classifier architected with fully connected layer.
Before dive into detail of gluon implementation, let’s consider dimensionality of embedding and feature maps. After data going through embedding layer, for each sentence, we have two dimensional matrix of size $N \times e$, where $N$ is the number of words in sentence (the same as defined above) and $e$ is the dimensionality embedded each word into. That means each row means a embed word and we have word-many rows in the matrix. In gluon, there is no way to apply 1D convolution layer for matrix. So, even though it is 1D convolutional layer that we need for convolution, we have to use 2D convolutional layers with appropriate kernel size defined to act as if it is 1D convolutional layers.
For this, if we set the width of kernel as embedding size, then there is no room for 2D convolution layer to convolve with the data more than 1 time and the kernels are applied only in the direction of words.
Here is the way how convolution layers defined. Only relavant part of the code is displayed below and the working code is given gluon implementation
class Sentence_Representation(nn.Block):
def __init__(self, **kwargs):
super(Sentence_Representation, self).__init__()
for (k, v) in kwargs.items():
setattr(self, k, v)
with self.name_scope():
self.embed = nn.Embedding(self.vocab_size, self.emb_dim)
self.conv1 = nn.Conv2D(channels = 8, kernel_size = (3, self.emb_dim), activation = 'relu')
...
In this article, we used 4 convolution layers with kernel size 3,4,5, and 6. Each kernels has 8 channels and we have 8$\times$ 4 kernels $=$ 32 nodes as input for classifier.
def forward(self, x):
embeds = self.embed(x) # batch * time step * embedding
embeds = embeds.expand_dims(axis = 1)
_x1 = self.conv1(embeds)
_x1 = self.maxpool1(_x1)
_x1 = nd.reshape(_x1, shape = (-1, 8))
_x2 = self.conv2(embeds)
_x2 = self.maxpool2(_x2)
_x2 = nd.reshape(_x2, shape = (-1, 8))
_x3 = self.conv3(embeds)
_x3 = self.maxpool3(_x3)
_x3 = nd.reshape(_x3, shape = (-1, 8))
_x4 = self.conv4(embeds)
_x4 = self.maxpool4(_x4)
_x4 = nd.reshape(_x4, shape = (-1, 8))
_x = nd.concat(_x1, _x2, _x3, _x4)
THe dimensionality of embedding is $B\times N \times e$, where $B$ is batch size. When we feed word embeddings to convolution layers, we have to expand dimension of embedding since 2D conv layer takes 4-dimensional array as its input, specifically, $B\times C \times H \times W$, where $C$ means channel, $H$ means height, and $W$ means width. (batch size $\times$ channel $\times$ height $\times$ width). As is described above, we consider $N$ as $H$, and $e$ as $W$. We are missing channel part of convolution input, and we just put 1 as input channel by expand dimension in the axis of 1 since we don’t have channel for text.
Result
It still shows excellect performance of accuracy 0.99. There are just 35 sentences misclassified and some of them look like as follows:
that not even an exaggeration and at midnight go to wal mart to buy the da vinci code which be --- Label:1.0
ok time to update wow have update for a long time ok so yeah watch over the hedge and mission --- Label:1.0
hey friends know many of be wonder where have be well last week go to a special screening of mission --- Label:1.0
hate though because really like mission impossible film so feel bad when go see in theater since put money in --- Label:1.0
mission impossible do kick ass and yes jessica be pretty damn dumb --- Label:1.0
harry potter and the philosopher stone rowling strangely a fan of hp fanfic but not of the book --- Label:1.0
child text fantasy perhaps most obviously be often criticize for oversimplify the struggle of good evil harry potter may be --- Label:1.0
for that but since be fault be into harry potter --- Label:1.0
harry potter be good but there only of those --- Label:1.0
also adore harry potter and hogwarts --- Label:1.0
well at least harry potter be real good so far --- Label:1.0
decide how want the harry potter to go --- Label:1.0
harry potter the goblet of fire be good folow on from the other movie --- Label:1.0
keep gettt into little want harry potter fit and have to watch which also can wait till in out in --- Label:1.0
harry potter be a story of good conquer evil and the friendship that be form along the way --- Label:1.0
and snuck in and go to springer brokeback mountain be finally see --- Label:1.0
think people be more tired of the mission impossible franchise than tom cruise --- Label:0.0
so run off because hated top gun mission impossible cocktail --- Label:0.0
I will leave it as a question for the readers of this article if those erroneous sentences deserve or not.
Reference
- https://arxiv.org/pdf/1510.03820.pdf
- http://www.aclweb.org/anthology/D14-1181
- http://docs.likejazz.com/cnn-text-classification-tf/#fn:fn-3