시작하며
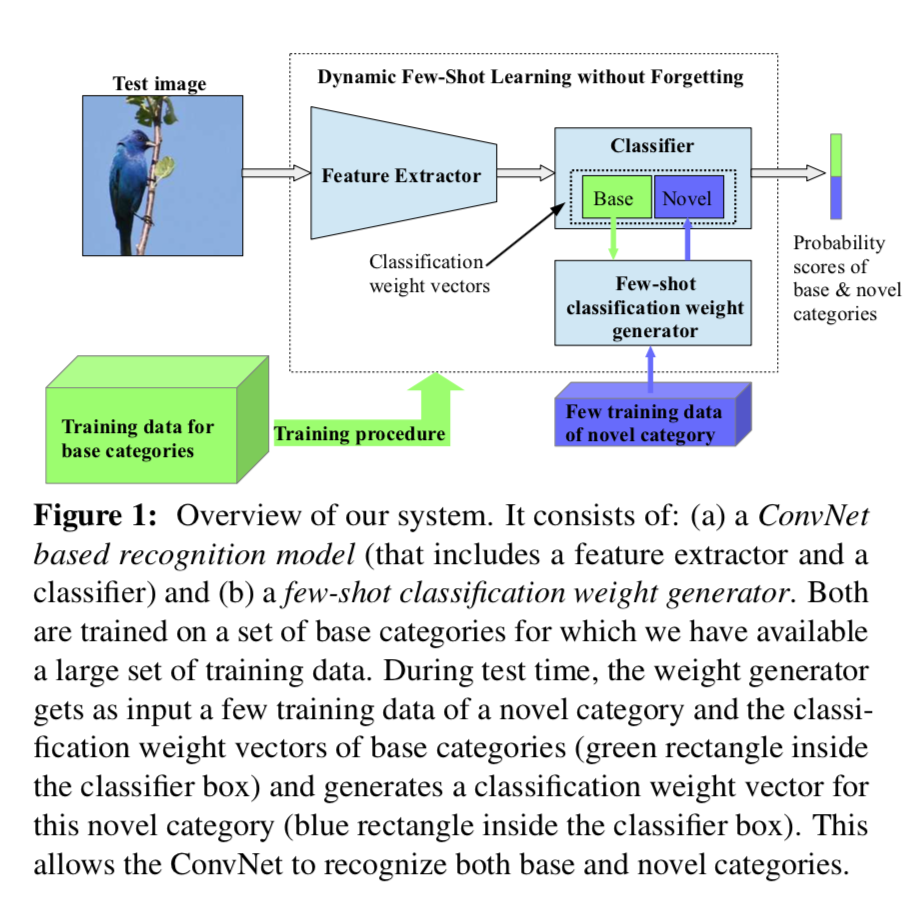
데이터 분석에 있어서 비지니스 환경 하에서는 언제나 imbalance 문제에 시달리게 됩니다. 새로운 상품은 계속 나오고 그 상품이 충분히 팔리기 전에 뭔가를 알고 싶어하는 마음이 큰 거죠. 그런 정보가 있으면 보다 효과적으로 새로운 상품을 고객에게 appeal할 수 있을 거니깐요.
Few shot learning은 이러한 문제를 해결하기에 아주 적합한 모형입니다. 되기만 하면 말이죠. 그러한 가능성을 tapping해보는 관점에서 Dynamic Few-shot Visual Learning without Forgetting을 읽는 중에 정리도 할겸 posting 하고자 합니다. Few-shot learning은 약 2~3년 전쯤에 한참 화제가 되다가 한동안 잠잠했었는데요. 올해 초부터 다시 화제가 되고 있는 분야입니다. 그 중심에서는 BAIR group에서 발표한 MAML과 SNAIL이 있습니다. MAML이 초기값 설정, SNAIL이 episode를 학습시키는 커다란 두 줄기의 few shot learning을 대표하는 방법이라면, 이 논문에서 제안하는 방법은 이들과는 다른 좀 새로운 시도로 보입니다.
Few-shot learning
논문에서는 기존의 transfer learning을 비롯해서 여러가지 few shot learning 방법들이 학습의 속도와 catastrophic forgetting 문제는 제대로 해결하지 못했다고 이야기 합니다. 그래서 이 논문에서는 그 문제를 해결하고자 했는데요. 성능을 보면 기존의 방법들보다 많이 좋기는 합니다.
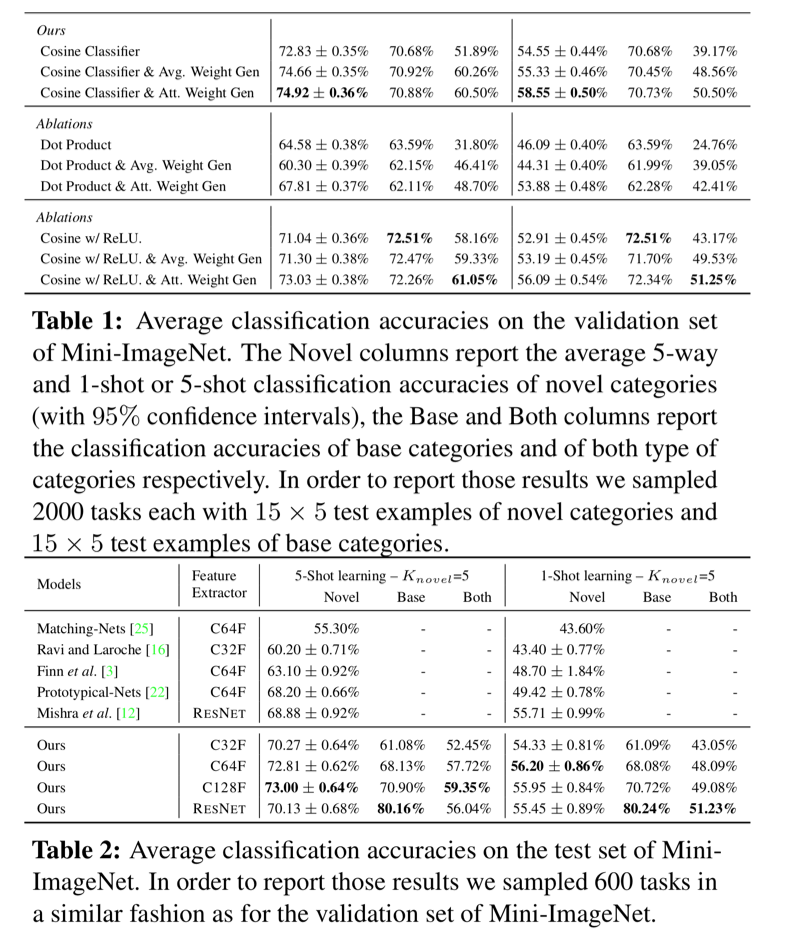
간단하게 요약해서 알고리즘을 설명하자면, 신경망의 weight들이 각 class별의 특성을 보유하고 있고, 따라서, 새로운 범주(novel category)로 분류해야 할 때, 몇개의 sample의 feature map을 활용하여, 새로운 범주로 분류하기 위한 신경망을 구축한다는 것입니다. 새로운 category의 weight값을 구하는 방법은 가장 쉽게는 feature map 값들의 평균의 함수로 구할 수도 있지만, 이 논문에서는 attention mechanism을 사용하는 것을 제안하고 있습니다. (Few-shot classification-weight generator based on attention). 이러한 과정은 이전의 경험으로부터 학습하는 인간의 학습과정과 닮아 있다고 합니다만, 이렇게 weight를 직접 조정하는 방법이 전혀 다른 domain의 분류 문제들에서는 어떤 성능을 발휘할지 잘 모르겠기는 합니다. 아마도 새로운 문제에 적용하기 보다는 이미 존재하는 문제를 보다 많은 category의 분류 문제로 확장하는 데에 도움이 되는 방법인 것 같습니다.
결국 새로운 weight를 update해서 새로운 범주를 분류할 수 있는 weight를 구한 다음, 이들을 모두 하나의 신경망으로 간주하고 기본 범주와 새로운 범주를 하나의 문제로 놓고 분류 문제를 풀겠다는 것입니다. 이 때 각각 다른 경로를 통해서 얻은 weight는 서로 다른 scale을 가지고 있을 수가 있는데 이를 scale에 구애받지 않고 합치기 위해서 신경망의 마지막 layer를 단순 weight과의 내적이 아니라 cosine similarity를 구해서 분류하게 됩니다.
Methodology
먼저 기본적인 셋업은 다음과 같이 데이터의 형태로 표현할 수 있습니다. 기본적으로 이 방법은 2단계 학습 구조를 가지고 있습니다. 첫 번째 학습에는 많은 데이터를 이용해서 base category를 잘 구분해 낼 수 있는 base category classifier를 학습힙니다. Base category를 구분하기 위해 쓰인 train data를 다음과 같이 나타냅니다.
이렇게 base category로 base classifier를 학습한 후에는 데이터가 많지 않은 novel category를 위해 2차 학습을 진행하게 되는데, 여기에 사용되는 데이터는 다음과 같이 표현합니다.
ConvNet-base recognition model
분류 작업은 CNN 기반의 신경망을 통해 이루어집니다. $K_{base}$개의 범주를 label로 두고 back prop으로 학습하는 일반적인 신경망과 다를 것이 없지만 1가지 다른 점은, 마지막 layer가 cosine similarity로 이루어진다는 점입니다. 만약 5개의 layer가 있으면 이 논문에서는 앞의 4개 layer를 feature extractor라고 부르고, 마지막 1개 layer를 classifier라고 부릅니다. 일반적으로도 그렇게 부르기는 하지만, 보다 명확한 이해를 위해 이를 다시 한번 강조했다고 볼 수 있습니다.
Feature extractor는 모수, $\theta$,를 가지는 신경망, $F(\cdot \vert \theta)$,로 표현합니다. Classifier는 $K_{base}$ 개의 base class에 대한 weight, $W_k^{ * }$,을 모두 포함하는 모수 집합, $W^{ * } = { w_k^* \in \mathbb R^d }_{k= 1}^{K^{ * }}$,을 전체 모수로 가지는 $C(\cdot \vert W^{ * })$로 표현을 합니다. Classifier는 결국 $K^{ * }$개의 classification vector로 이루어져 있고, 이 classification vector가 각 base class에 대한 정보를 압축하고 있다고 간주합니다. 이 classifier를 통과 하면 $K^{ * }$의 길이를 가지는 score값 vector, $p = C(z\vert W^{ * })$를 최종적으로 얻습니다.
Base category와 novel category는 feature extractor를 공유합니다. 이렇게 공유된 feature extractor를 통과한 결과를 비교해서 비슷한 class의 weight vector를 새로운 데이터로 업데이트 해서 novel category의 classifier로 사용합니다.
단일 training에서는 base category를 잘 분류하는 classifier를 찾는 것, 다시 말하면 최적화된 모수집합 $W^*$를 찾는 데 주력합니다.
위에서 언급한 것과 같이 이 논문에서 사용된 classifier는 기존의 classifier와는 달리 cosine similarity를 가집니다. 데이터가 이미 feature extractor를 통과해서 $z$라는 feature extract(혹은 일반적으로는 feature map)을 얻었다고 하면, 일반적으로는 $p=C(z\vert W^*)$를 구하기 위해서 먼저 score $s_k, k =1 , \ldots, K_{base}$를 구하고 이들 score를 softmax layer를 통과시켜 각 category에 대한 최종 확률을 얻습니다. 1차 학습이 아니라 신규 범주가 포함되어 있는 2차 학습의 경우 weight vector를 구하는 방법은 base category와 novel category에 따라 크게 다릅니다. base category에 대한 weight들은 아주 많은 데이터로 서서히 학습이 된 안정적인 weight라면 weight generator를 통해 학습된 novel category의 weight값은 아주 작은 data로 학습이 되는만큼 안정성이 떨어지는 weight일 것입니다. 그러므로 만약 classifier에서 weight vector와 feature vector, $z$를 그냥 곱한후에 softmax를 취하게 되면 하나의 category에 몰리는 현상이 발생할 수도 있습니다. 이런 경우를 대비해서, 이 논문에서는 weight과 feature extract를 모두 normalize한 후에 내적을 취함으로써 cosine similarity를 구하는 것과 같은 연산을 진행합니다.
이렇게 함으로써 서로 다른 pipeline으로부터 얻은 weight vector의 scale에 영향을 받지 않고 분류를 진행할 수 있습니다. 이 부분이 이 논문의 가장 큰 contribution 중의 하나라고 저자들은 이야기 합니다.
여기서 $\tau$는 또다른 모수로서 scalar값을 지닙니다. 오로지 방향성만 감안하겠다는 뜻으로 weight vector의 norm에는 의존하지 않습니다. 마지막에 relu layer를 태우지 않아도 non-linearity를 잃지 않을 수 있고, 양수와 음수 모두 지닐 수 있습니다. 이렇게 나타내면 분류를 좀더 잘 할 수 있다고 논문에서는 이야기합니다.
또하나의 포인트
Weight의 scale에 구애받지 않고, 분류 작업을 할 수 있다는 장점 이외에도 cosine similarity를 사용하게 되면 feature extractor를 base category의 데이터냐 novel category의 데이터냐에 상관없이 잘 일반화 해서 학습할 수 있다고도 하네요. 그 이유인 즉슨, 추출된 feature activation이 ground truth label의 weight vector와 정확히 일치하도록 유도하기 때문에, $l_2$ 정규화 된 feature extract들의 inter class variation이 줄어드는 데에 도움을 주기 때문이라고 합니다. 그렇다기 보다는 그렇게 해석할 수 있다 정도가 맞겠습니다.
In fact, it turns out that our feature extractor trained solely on cosine-similarity based classification of base categories, when used for image matching, it manages to surpass all prior state-of-the-art approaches on the fewshot object recognition task.
Few-shot classification weight generator
1차로 학습된 결과를 바탕으로 새로운 범주에 대한 weight를 구하게 되는데, 이 과정에서, base category의 특성을 활용합니다. 새롭게 추가되는 $K_{novel}$개의 novel category에 대해 각각 $\phi$를 모수로 하는 classification weight generator, $G(.,.\vert \phi)$,가 있습니다. 만약 $n$ 번째 novel category의 $i$번째 데이터, $x’{n, i}$,가 에 들어가면 $z’{n,i}$를 얻습니다. 다시 말하면, 다음과 같습니다.
이 $z’_{n,i}$와 함께 base category의 weight값을 input으로 사용하여 $G(.,.\vert \phi)$는 새로운 범주의 weight vector를 update합니다. 이런 과정을 새로운 범주 전체에 대해서 반복하고, 다음과 같은 새로운 범주에 대한 weight vector의 집합을 얻게 되는 것입니다.
결국 우리는 base category와 함께 novel category에 대해 분류를 할 수 있는 weight 집합을 얻었습니다.
이미 학습되어 있는 base classifier의 weight를 모두 가지고 있을 것이므로 기존 범주에 대한 정확도의 훼손 없이 새로운 범주를 분류해 낼 수 있게 된다고 합니다.
Feature averaging based weight inference
Cosine similarity를 바탕으로 한 ConvNet을 쓰는 이유가 feature extractor를 통과한 feature vector가 각 class별로 군집해 있도록 하는 것이라고 위에서 설명을 했습니다. 이 아이디어에 근거해, 새로운 범주에 속하는 여러가지 $N’$개의 input으로부터 얻은 feature extract의 평균을 이용해서 weight를 구할 수 있습니다.
최종 weight는 다음과 같이 구합니다.
Attention-based weight inference
Attention은 요즘 새롭게 소개되는 신경망에는 약방의 감초처럼 등장하는 개념입니다. 단순 평균보다는 중요한 요소에 중요도를 더 주자는 건데, 어느 요소에 얼만큼 중요도를 부여할지를 또 다른 신경망이 판단하도록 합니다. $K_{base}$개의 base category에 대해 다음과 같이 attention을 구합니다.
여기서 $\phi_q \in \mathbb R^{d\times d}$는 feature extractor를 query로 만들어주는 행렬로서 $\phi_q\bar z’_i$는 $k_b$라는 key vector와 함께 attention을 구해냅니다. Attention을 구할 때에도 dot product 대신에 cosine similarity를 사용합니다.
이렇게 구한 후에
처럼 weight을 구합니다.
Training procedure
Train ConvNet
ConvNet을 학습시킨다고 하는 것은 $F(\cdot\vert \theta)$와 $C(\cdot \vert W^*)$를 학습시킨다는 것을 의미합니다. ConvNet과 few-shot classification weight generator $G(\cdot, \cdot \vert \phi)$를 학습시키기 위해 먼저 base category만으로 학습을 진행합니다. 이 단계는 두 단계로 이루어집니다. 각각의 단계에서 다음의 cross entrophy loss를 최소화합니다.
1st training stage:
모수를 $W^* = W_{base} = {w_b}{b= 1}^{K{base}}$로 설정하고 feature extractor와 classifier만을 학습합니다.
2nd training stage:
두번때 단계에서는 classification weight generator를 학습하는 단계입니다. 여기에서는 base classifier의 모수들을 고정시킨 채로 학습을 할 수도 있고, 모든 모수를 학습시킬 수도 있겠습니다. 가장 중요한 부분은 학습셋을 어떻게 구성하는가일 것입니다. 그렇게 많지 않은 숫자(논문에서는 일반적으로 novel category당 5개 미만의 example을 생각합니다.)의 novel category의 샘플 숫자에 맞추어, base category로부터 fake example을 matching시켜서 classification weight generator를 학습시키는 것이 핵심입니다.

아무리 봐도 문장이 이상한 것 같은데요. 어쨌든 attention mechanism을 사용할 때에는 attention mechanism에 이용된 base category는 학습셋에 포함하지 말라는 내용입니다. 구현해 가면서 정확한 의미를 생각해 보도록 하려고 합니다.
마치며
일단은 논문 전반에 대해서 훑으면서 큰 그림을 그려보았습니다. MAML이나 SNAIL보다는 훨씬 직관적으로 이해하기 쉬운 모형이라는 생각은 변함이 없습니다. cosine similarity를 마지막에 사용하는 면도 좀 재미있구요. 하지만, 구현이 그렇게 쉽지는 않을 것 같은 것이, training phase에 따라 서로 다른 data의 pipeline을 타야 하고, SNAIL만큼은 아닐지 몰라도 학습에 사용되는 데이터의 구조를 잘 만들어 내야 하다 보니, data loader의 프로그램이 쉽지는 않을 것 같다는 생각이 듭니다. 이상 짧지만 농도 짙은 글을 마치고, 다음에는 gluon으로 어떻게 구현할 수 있을지에 대해 다루도록 하겠습니다.